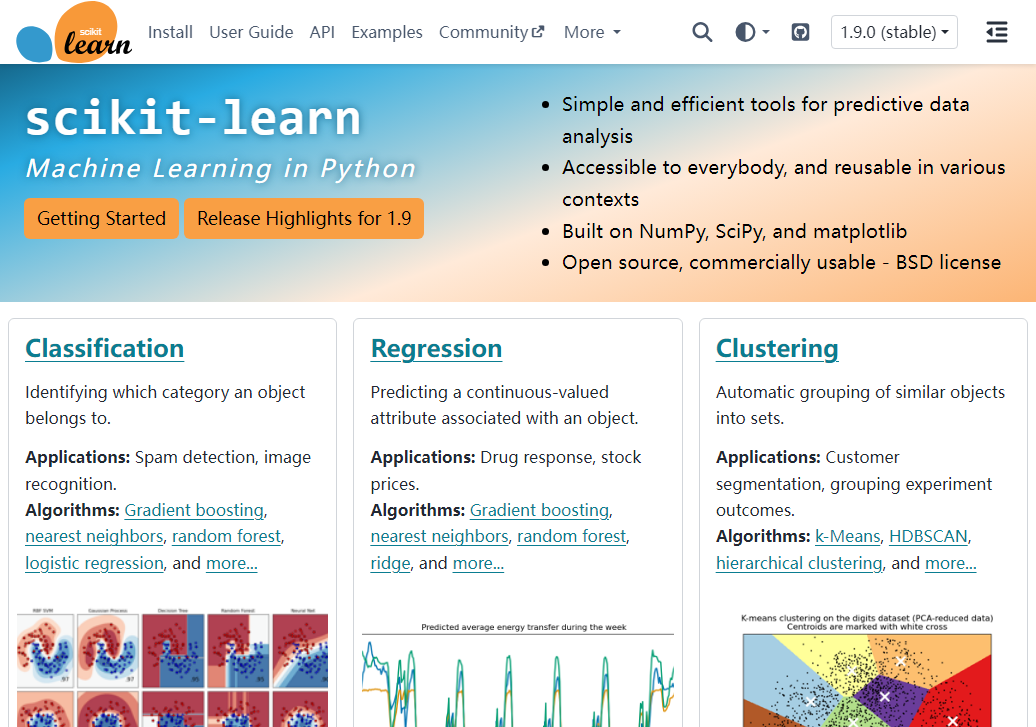
所有模型遵循相同的 fit/predict/transform 模式,降低学习成本,代码可读性与可维护性极强。
内置分类、回归、聚类、降维、模型选择与评估模块,从经典统计到集成方法一应俱全。
提供标准化、编码、特征选择等丰富工具,并支持 Pipeline 串联,简化复杂工作流。
David Cournapeau 在 Google Summer of Code 项目中启动 scikit-learn 的前身 —— 一个基于 SciPy 的机器学习工具包。该项目最初名为 scikits.learn,遵循 SciKits 的命名规范,旨在为 Python 生态提供统一的机器学习接口。
项目迎来第一批核心维护者:Fabian Pedregosa、Gaël Varoquaux、Alexandre Gramfort 等人。同年,scikits.learn 更名为 scikit-learn,并发布了首个公开版本(0.1 beta),实现了简单的监督学习算法(如线性回归、SVM)以及基本的交叉验证工具,社区开始逐步关注。
0.8 版本正式释出,引入决策树、随机森林以及基于最近邻的分类器,并大幅优化了内部 API 的一致性。同年,文档系统(基于 Sphinx)和在线教程雏形上线,scikit-learn 开始在学术论文中被引用,成为统计学习领域的推荐工具。
发布 0.11 与 0.12 版本,首次支持谱聚类、高斯混合模型以及特征选择模块。社区贡献者数量显著增长,项目托管在 GitHub 并采用 open source 合作模式。该年被视作 scikit-learn 走向成熟的转折点,用户群从科研人员扩展到数据行业从业者。
0.14 版本成为里程碑式更新:引入管道(Pipeline)机制,支持构建可组合的机器学习工作流;增加字典学习、潜在 Dirichlet 分配(LDA)等主题模型。同年,scikit-learn 在 PyCon 等会议上进行专题演讲,被业界公认为 Python 机器学习标准库之一。
0.17 版本发布,包含弹性网络、分层聚类以及优化过的梯度提升(Gradient Boosting)实现。新增了用于模型比较的 `cross_val_score` 简化接口。该版本还淘汰了旧版 `BaseEstimator` 的某些过时方法,向更严格的 API 规范过渡。
0.19 版本集成了许多用户请求的功能:增加 `MLPClassifier` 和 `MLPRegressor`(多层感知机),以及 `NuSVR` 等支持向量回归变体。与此同时,官方文档增加了大量实例教程,并推出 `scikit-learn-tutorial` 这个独立项目以帮助新用户快速上手。
0.20 版本显著改进了性能与内存管理:支持分块训练(partial_fit)的多元朴素贝叶斯、多项式核 SVC 的优化,并引入 `ColumnTransformer` 以方便处理混合类型数据。该版本还是最后一个支持 Python 2.7 的系列,为后续彻底转向 Python 3 铺垫。
0.24 版本引入孤立森林(Isolation Forest)异常检测、HistGradientBoosting(基于直方图的梯度提升)以及迭代式特征选择。此版本还启用了对稀疏矩阵的更好支持,并开始实验性地采用 `__version__` 与 `setup.py` 的现代打包标准。
9 月,scikit-learn 正式发布 1.0 版本,标志着项目进入稳定语义化版本阶段。1.0 提供大量重要更新:增广 `SparsePCA`、`MultiTaskElasticNet`,并内置了 `common_criteria` 用于快照评估。同时,项目确立每年两次主要版本发布的节奏,并开始全面支持 Python 3.8+。
1.1 版本新增 `TargetEncoder`(目标编码器)、`QuantileRegressor`(分位数回归),以及更灵活的 `RFECV` 参数。1.2 版本强化了对 `PolynomialFeatures` 稀疏矩阵的支持,并将 `pairwise_distances` 的底层计算切换到更高效的 NumPy 后端。社区治理文档也得到完善,明确维护者与贡献者协作规范。
1.3 版本聚焦于可解释性与大规模数据处理:引入 `permutation_importance` 的交互式可视化,并支持 `Array API` 标准(如 CuPy 和 JAX)的实验性加速。同年,scikit-learn 官网重新设计,采用更友好的响应式布局,并增加针对移动端的快速导航。
1.4 和 1.5 版本相继发布。1.4 增添了 `HDBSCAN` 算法(层次密度聚类)以及 `SelectiveSearch` 特征选择。1.5 则提升了 `RandomForest` 与 `ExtraTrees` 的并行效率,并正式宣布停止对 Python 3.8 的支持,将最低 Python 版本提升至 3.9,确保利用最新的 NumPy 和 SciPy 优化。